
Fine-Tuning → Making AI Models Smarter
Oct'25 - Issue #69

Welcome to the AI Insights tribe. Join others who are receiving high-signal stories from the AI world. In case you missed it, Subscribe to our newsletter.AI models are powerful, but they aren’t perfect out of the box. Sometimes, you need them to understand your specific data, language, or use case better, and that’s where fine-tuning comes in. It’s about taking a general AI model and making it smarter to meet your unique needs.
In this guide, I will break down what fine-tuning actually is, why it matters, and most importantly, the different approaches you can use to fine-tune a model without burning through your entire budget or losing your sanity.
What is Fine-Tuning?
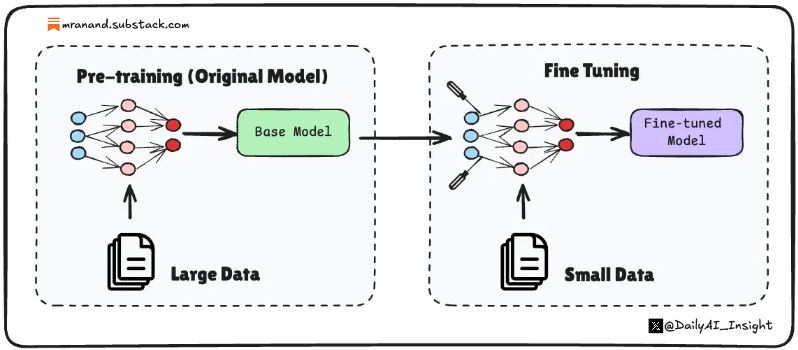
Fine-tuning is a machine learning process where an already trained, general-purpose AI model is further trained on a smaller, task-specific dataset to adapt its existing knowledge and improve performance on a specialised task.
Think of it like this: imagine you hired a brilliant Harvard graduate who knows a little bit about everything. Finetuning is like giving them a three-month intensive training in your specific industry, such as law, healthcare, or customer support. They already have the foundational knowledge, you’re just teaching them the nuances of your domain.
Reasons/Advantages of Fine-Tuning
1. Cost-Effective Development: Training a large language model from scratch can be costly, requiring millions of dollars and substantial computational resources. Finetuning, on the other hand, works with models that have already learned the basics of language, reasoning, and pattern recognition. You’re only paying to teach it to your specific use case, which can cost a fraction of the original training expense.
2. Faster Time to Market: Why wait months when you can have a working model in days or weeks? Fine-tuning drastically reduces development time because you’re not starting from zero. Your base model already understands grammar, context, and general knowledge; you’re simply adding the finishing touch.
3. Superior Performance on Specific Tasks: A general-purpose model may yield decent results, but a fine-tuned model will excel at your specific task. If you’re building a medical diagnosis assistant, a model fine-tuned on medical literature will vastly outperform a generic model, as it understands medical terminology, treatment protocols, and diagnostic criteria with much higher accuracy.
4. Data Efficiency: You don’t need massive datasets to finetune effectively. While training a model from scratch might require billions of tokens, finetuning can achieve impressive results with thousands or even hundreds of carefully curated examples. This is especially valuable when working in specialised domains where data might be limited.
5. Customisation and Control: Finetuning gives you control over your model’s behaviour, tone, and outputs. Want your customer service bot to match your brand voice? Want your coding assistant to follow your company’s style guide? Finetuning enables precise alignment of the model with your requirements, resulting in a truly customised AI solution that feels native to your organisation.
Different Ways to Fine-Tune Models
There are several approaches to finetuning, each with its own trade-offs. Let’s break them down.
1. Programmatically: The Traditional Approach
This is the OG way to fine-tune, write code, manage infrastructure, and get your hands dirty with Python and machine learning libraries.
Here’s how it typically works: let’s say you’re building a legal AI application. You head over to Hugging Face, browse through thousands of models, and find one that suits your use case, maybe a model that’s been pre-trained on general text but needs to understand legal jargon, case law, and regulatory language.
You download the model, prepare your dataset of legal documents, contracts, and case precedents, and then write scripts using libraries like Hugging Face Transformers, PyTorch, TensorFlow, or Unsloth. You configure your training parameters, such as learning rate, batch size, and number of epochs, and then either start your GPU cluster or rent cloud GPUs from providers like AWS, Google Cloud, or Azure.
The process involves data preprocessing (cleaning, tokenisation, and formatting), setting up training loops, monitoring loss curves, validating performance on test sets, and iterating until the desired results are achieved. You’ll write training scripts, manage checkpoints, handle out-of-memory errors, debug CUDA issues, and probably lose sleep over vanishing gradients.
But this approach gives you complete control. You can implement custom loss functions, experiment with different architectures, try advanced techniques like LoRA (Low-Rank Adaptation) or QLoRA for efficient fine-tuning, and optimize every aspect of the training process. You can use mixed-precision training to accelerate learning, gradient accumulation to achieve larger effective batch sizes, and fine-tune hyperparameters to extract every bit of performance.
If you want to see how this looks in practice, check out these examples:
Fine-tuning with Unsloth: Fine-tuning Granite-4.0 guide
Fine-tuning with Hugging Face: Transformers training guide
Fine-tuning with TensorFlow: Transfer learning with TensorFlow and Keras
Advantages of this approach and why you should go with it:
Complete Control: You have full control over every aspect of the training process, from data preprocessing to modifications to the model architecture. Want to freeze certain layers? Implement custom regularisation? Use a specific learning rate schedule? You can do it all.
Flexibility and Experimentation: You can experiment with cutting-edge techniques, implement research papers, and try novel approaches that aren’t available in no-code platforms. The entire ML research ecosystem is at your fingertips.
No Vendor Lock-in: Your code, your infrastructure, your models. You’re not dependent on any platform or service. You can switch cloud providers, move your solution on-premises, or distribute it as needed.
Deep Learning and Debugging: When things go wrong (and they will), you can dig deep into logs, inspect gradients, visualise activations, and understand exactly what’s happening. This level of insight is invaluable for troubleshooting and optimisation.
Cost Optimisation for Scale: If you’re fine-tuning dozens of models or working at scale, programmatic approaches can be more cost-effective in the long run. You can optimize resource usage, implement efficient batching strategies, and run training on spot instances or preemptible VMs to save money.
2. User-Friendly Approach
Because of the technical knowledge, time, resources, and expertise needed to finetune models programmatically, companies have started building tools that make it easy to finetune models without writing a single line of code, or at least minimise the code you need to write.
You just come to the platform, and using their user interface, you’ll be able to finetune models to your taste. Upload your data, select your base model, configure a few settings, and hit “train.” The platform handles the infrastructure, optimisation, and deployment.
A great example is Nebius AI Studio.
Nebius AI Studio is a platform that enables you to utilize various AI models and fine-tune them at a significantly reduced cost. It also allows you to deploy your own models with minimal hassle. With Nebius AI, you don’t need to worry about the in-depth technical knowledge of distributed training, GPU management, or hyperparameter optimization.
You can easily fine-tune the models they provide using their intuitive UI, making it perfect for teams without dedicated ML engineers. But here’s the best part: even if you want to use code, they already have comprehensive documentation and walkthroughs for finetuning, making everything easy and accessible. They provide ready-to-use guide, SDK libraries, and API endpoints that abstract away complexity while still offering flexibility.
The platform functions as a complete inference solution, automatically handling data versioning, experiment tracking, model registry, and deployment pipelines. With access to powerful GPU infrastructure, you can compare different finetuning runs, roll back to previous versions, and deploy models to production with a few clicks, all within a single unified platform.
Advantages of this approach and why you should choose it:
Lower Barrier to Entry: You don’t need a PhD in machine learning. Product managers, domain experts, and developers with basic technical skills can effectively fine-tune models. The learning curve is dramatically reduced.
Faster Iteration: With pre-built infrastructure and optimised training pipelines, you can iterate much faster. What might take days to set up programmatically can be done in hours using these platforms.
Managed Infrastructure: No need to worry about provisioning GPUs, managing clusters, handling failures, or optimising resource allocation. The platform handles all infrastructure management, letting you focus on your data and use case.
Cost Transparency and Optimisation: These platforms often provide clear pricing models and automatically optimise resource usage. They can spot-check instances, use efficient batch sizes, and terminate idle resources, potentially saving you money compared to rolling your own infrastructure.
Built-in Best Practices: The platforms incorporate best practices from thousands of fine-tuning runs, including optimal hyperparameters, proven training strategies, and efficient data handling. You benefit from collective knowledge without needing to be an expert yourself.
Integrated MLOps: Most platforms include standard features such as experiment tracking, model versioning, performance monitoring, and deployment pipelines. You get a complete MLOps workflow without having to build it yourself.
No Vendor Lock-in: Nebius offers flexibility with no vendor lock-in, allowing you to bring and deploy fine-tuned models from external sources or other providers. This ensures portability, interoperability, and freedom to choose the best tools for your workflow.
You can check few good notebooks on distillation or fine-tuning with Nebius AI Here - https://github.com/nebius/ai-studio-cookbook
3. API Approach: Train Without Infra Headache
You can also finetune a model by simply making API calls to specialised finetuning services. This approach combines the simplicity of tools with the flexibility of programmatic access. You write code, but the service handles the infrastructure, optimization, and training management.
A great example is Tinker.

Tinker is a training API for researchers and developers who want to finetune LLMs without managing infrastructure. It’s a relatively new platform gaining traction because it lets you focus on your data and algorithms. At the same time, they handle the heavy lifting of distributed training, gradient synchronisation, and fault tolerance.
Tinker lets you fine-tune open-weight models like the Qwen and Llama series, including large mixture-of-experts models like Qwen3-235B-A22B. You can even finetune massive models that would usually require complex distributed training setups. Tinker abstracts that complexity behind simple API calls.
Here’s what makes it powerful: You can download the weights of your trained model to use outside of Tinker, for example, with your inference provider of choice, such as Nebius AI as shared above, or your own infrastructure. You’re not locked into their ecosystem for serving your models.
The workflow is straightforward: Prepare your dataset, make an API call to start training with your chosen base model and hyperparameters, monitor progress through their dashboard or API endpoints, and download your finetuned weights when training completes. You can integrate this into your CI/CD pipelines, automate model updates, and manage everything programmatically without dealing with infrastructure. For detailed documentation on fine-tuning with Tinker, check out their comprehensive guide.
Advantages of this approach and why you should choose it:
Developer-Friendly Integration: APIs are familiar territory for developers. You can integrate fine-tuning into your existing workflows, CI/CD pipelines, and automation scripts without learning new tools or platforms.
Infrastructure Abstraction: You benefit from programmatic control without managing infrastructure. No provisioning GPUs, no configuring clusters, no debugging distributed training failures.
Scalability on Demand: Need to finetune one model or a hundred? The API scales automatically. Your own infrastructure capacity does not limit you, and you don’t need to plan for peak usage.
Model Portability: API-based services (like Tinker) let you download your model weights, avoiding vendor lock-in for inference. You train via API, but deploy wherever makes sense for your use case.
Cost Efficiency for Sporadic Use: If you’re not constantly fine-tuning, API-based pricing (pay-per-job) can be significantly more economical than maintaining your own infrastructure or paying for platform subscriptions.
Researchers and Builders can concentrate on data quality, model evaluation, and application integration, rather than grappling with infrastructure, environment setup, and operational challenges.
You can learn more about Tinker by checking their Cookbook👇
Secure Packaging and Deploying Your Fine-Tuned Models
Once you’ve finetuned your model, the next challenge is packaging and deploying it reliably. Fine-tuning model is a huge challenge and often done for critical use-cases like security, gov-tech, med-tech and other similar things. This is where tools like KitOps and Jozu come in; they solve the “last mile” problem of getting your model from training to production.
What is KitOps?
KitOps is an open-source tool that helps teams securely package, version, and deploy AI/ML models using familiar DevOps practices. Think of it like Docker for AI models: it bundles everything your model needs (weights, datasets, config, documentation) into a single, portable package called a ModelKit.
Just as PDFs standardise document sharing, KitOps standardises how AI/ML projects are packaged, shared, and deployed. It’s OCI-compliant, meaning it works with your existing container registries and DevOps tools. You can integrate it into CI/CD pipelines, eliminate “it works on my machine” problems, and share models between teams without ambiguity.
KitOps is trusted by security-conscious organizations, including security agencies and the US government, making it particularly valuable when working with sensitive data. If you’re handling medical records, financial information, or other confidential data and are deeply concerned about security, compliance, and maintaining complete control over your model artifacts, KitOps provides the way to keep everything within your own environment while still enabling collaboration and reproducibility.
What is Jozu?
Jozu builds on KitOps by adding enterprise features such as security, governance, and deployment automation. It’s a self-hosted and SaaS platform that helps you work with ModelKits directly from tools like Jupyter, MLflow, or Weights & Biases.
With Jozu Hub, models become first-class assets, versioned, signed, auditable, and ready for production. It provides greater security and privacy than public registries, making it ideal for regulated industries or organisations that need to keep their models and data private.
Together, KitOps and Jozu ensure you can package, version, secure, and deploy your fine-tuned models reliably, treating your AI models with the same value as the rest of your software infrastructure.
You can also fine-tune models for critical use cases using KitOps inside your workflow.
If you want to see how this looks in practice, check out these examples:
Fine-tuning with llama.cpp: Fine-tuning with KitOps
Fine-tuning SLM: Guide to Tune and Deploy 1st SLM
Also check 👇

Wrap-Up
Fine-tuning is one of the most potent techniques in modern AI development, enabling you to tailor general-purpose models to your specific needs without the high cost of training from scratch. Whether you choose the programmatic approach for maximum control, platforms like Nebius AI Studio for ease of use, or API services like Tinker for developer-friendly integration, there’s a path that fits your team’s skills, budget, and requirements.
And once you’ve finetuned your model, tools like KitOps and Jozu ensure you can package and deploy it reliably.
There’s another powerful approach gaining serious traction lately: distillation. Distillation is a technique where a large, powerful model (the “teacher”) is used to train a smaller, more efficient model (the “student”) to mimic its behaviour. Instead of fine tuning an existing model on your data, you’re creating a compact model that preserves most of the performance while being faster, cheaper, and easier to deploy.
Distillation can be particularly useful when you need low-latency inference, want to run models on edge devices, or simply can’t afford the computational costs of running large models in production. It’s becoming an increasingly popular alternative to fine tuning, mainly for teams that need production efficiency.
We’ll be diving deep into distillation in the coming weeks, exploring how it works, when to use it versus fine-tuning, practical implementation strategies, and real-world examples.
If you enjoyed this breakdown, I’d love to hear how you’re doing fine-tuning or any similar experiences!
👉 Follow our Newsletter on X: Daily AI Insights
Week in AI
RND1 - Radical Numerics released the most powerful base diffusion language model (DLM) to date.
Agentic Context Engineering - New framework that beats current state-of-the-art optimizers like GEPA by treating context as an evolving, structured space of accumulated knowledge.
Ring-1T - The open-source trillion-parameter thinking model built on the Ling 2.0 architecture.
nanochat - Andrej Karpathy dropped full-stack implementation of an LLM like ChatGPT in a single, clean, minimal, hackable, dependency-lite codebase.
New Fundings - Reflection AI and Mastra Agent framework got new funding.
Sukriya🙏🏼 See You Again Next Week! Till Then Keep Learning and Sharing Knowledge with Your Network
This is a really thorough breakdown of the fine-tuning landscape. I particularly appreciate how you've covered both the technical approaches and the more accsesible user-friendly platforms. The KitOps mention for secure deployment is a detail many guides overlook but it's crucial for production environments.