
AI Memory 101 → How Databases Became the Brain of AI Agents
Sep'25 - Issue #65

Welcome to the AI Insights tribe. Join others who are receiving high-signal stories from the AI world. In case you missed it, Subscribe to our newsletter.Today’s newsletter is brought to you by The Rundown AI!

Get the latest AI news, understand why it matters, and learn how to apply it in your work. Join 1,000,000+ readers from companies like Apple, OpenAI, NASA.
AI memory is quickly becoming the next big challenge in AI development. If LLM fine-tuning was about making models smarter, AI memory is about helping them remember — your data, your preferences, and the context of past conversations. If you’ve been wondering how databases suddenly became the backbone of “AI memory,” this is your guide.
Databases Have Been Here All Along – Now They're Powering AI Memory
Since the burst of ChatGPT and GPT-3 in 2020, people have been building applications with AI at an insane pace. From customer support chatbots to research assistants, everyone was chasing the dream of AI that doesn't just respond smartly but feels human.
But apart from making LLMs more intelligent and interactive with data, one problem has refused to go away: memory and context.
The problem is that AI forgets easily. It forgets what you told it five minutes ago, it forgets your preferences, it forgets the "whole point" of the conversation after enough back-and-forth. You could tell it you don't like coffee, and a few prompts later, it's recommending espresso. That's not human-like memory.
This gap sparked a wave of research and experimentation. How do we give AI agents persistent, human-like memory? How do we make them remember key facts about people over long periods and actually use them when making decisions? How do we make talking to AI feel like talking to a real person?
That question has led to several different approaches and databases was one of the central figure. Let's break them down.
1. The Fine-Tuned / Prompt Engineering Approach
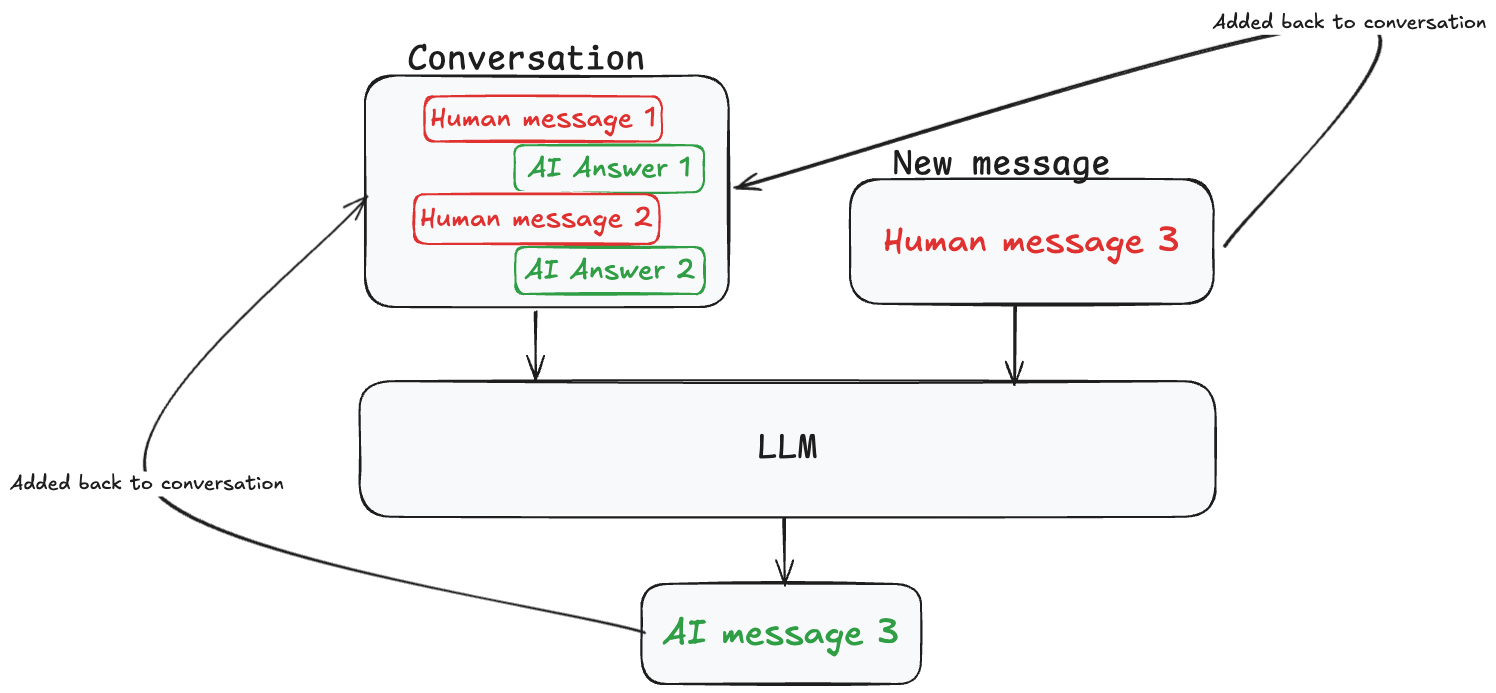
This was one of the earliest hacks people tried. The idea is just to feed the model its "memory" inside the prompt. Either fine-tune it with user data or prepend long conversation histories so it doesn't lose track.
How it works: The system maintains a running context of the conversation by concatenating previous messages into each new prompt. Some implementations use instruction tuning to teach the model specific memory behaviours, while others rely on in-context learning by providing conversation history as examples.
It was simple, fast, and worked for short contexts. Some papers and early frameworks relied heavily on this method, particularly before more sophisticated memory architectures emerged.
Pros:
Easy to implement with no extra infrastructure
Works fine for small, one-off use cases
Can be combined with instruction tuning
Zero latency for memory recall
Cons:
Becomes expensive as prompts get longer (token costs explode)
Context window limits mean you'll eventually get cut off
Doesn't scale for real long-term memory
No semantic organisation of information
2. Vector Databases as Memory (RAG-Based Approach)
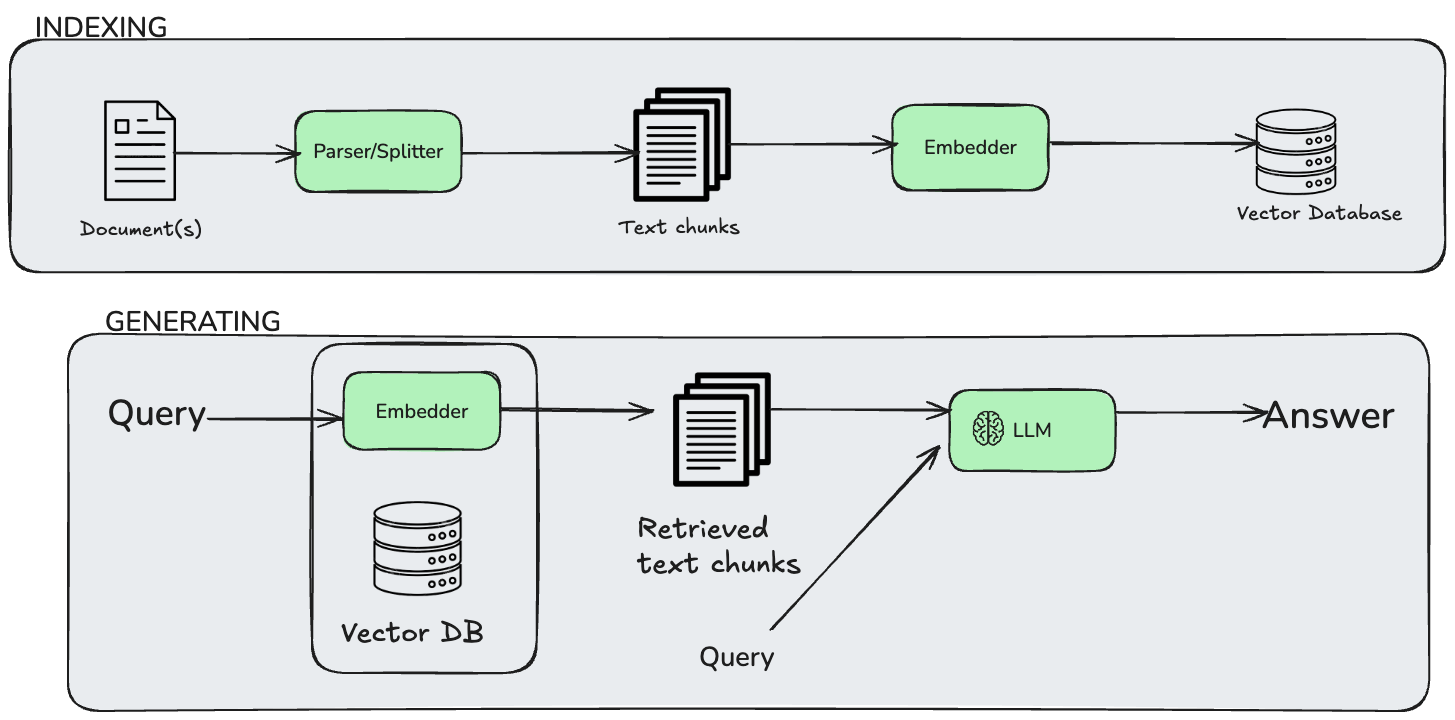
Then came the vector database approach, heavily influenced by Retrieval-Augmented Generation (RAG) research. Frameworks like Zep, Pinecone integrations, and tools like LangChain Memory leaned on embeddings. The idea was to store every piece of conversation as a vector, then use similarity search to recall relevant chunks when needed.
How it works: Each conversation turn, document, or piece of information gets converted into high-dimensional vectors using embedding models (like OpenAI's text-embedding-ada-002 or newer models). These vectors are stored in specialised databases like Pinecone, Weaviate, or Couchbase. When the AI needs to remember something, it converts the current query into a vector and finds the most semantically similar stored memories using cosine similarity or other distance metrics.
This approach was heavily influenced by the foundational RAG paper by Lewis et al. (2020) "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks", which showed how combining parametric (model) and non-parametric (retrieval) memory could significantly improve performance on knowledge-intensive tasks.
Recent comprehensive surveys, such as "A Comprehensive Survey of Retrieval-Augmented Generation" (2024), have demonstrated the evolution of RAG from simple retrieval to sophisticated memory systems.
This gave AI something closer to "searchable memory."
Pros:
Semantic recall: It finds things even if you phrase them differently
Flexible: It works across conversations, documents, and knowledge bases
Well integrated with modern AI stacks
Scales to large amounts of unstructured data
Cons:
Recall isn't always precise, as you can get noise and irrelevant results
It needs constant pruning/management to avoid bloat
Retrieval is probabilistic, not structured, and sometimes you miss key facts
It is poor at handling relationships between entities
The paper which introduced a new approach towards Agentic memory!
3. Graph Databases and Entity-Based Memory
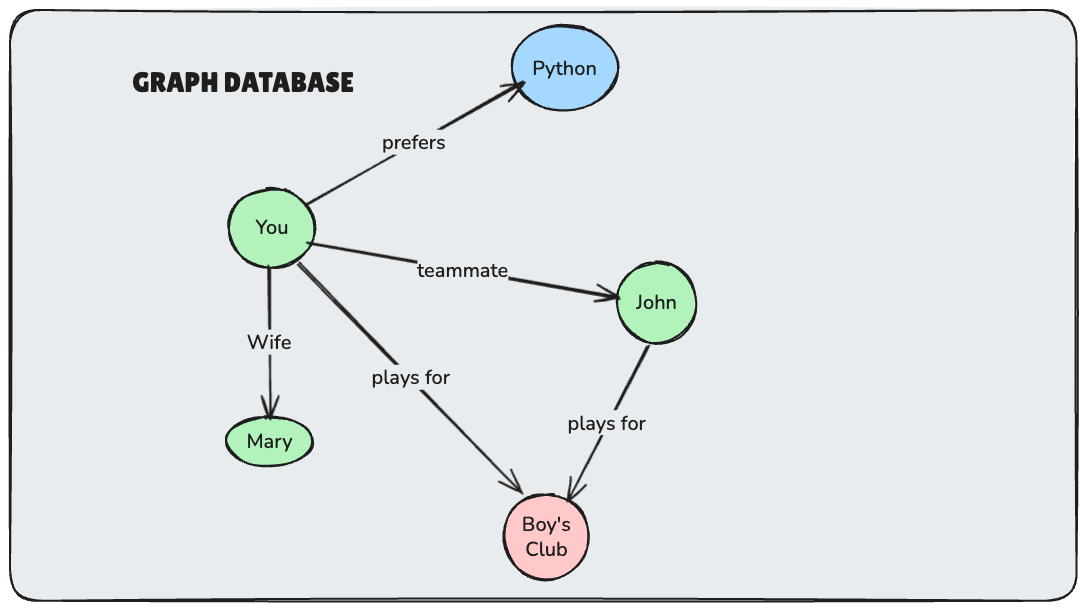
Another branch of research looked at graph databases or entity-relationship style memory. This approach has gained significant academic attention, with several notable implementations and research papers.
How it works: Instead of storing flat vectors, these systems build knowledge graphs where nodes represent entities (people, concepts, facts) and edges represent relationships. When you tell the AI "John is my teammate who prefers Python," it creates nodes for you, John, and Python, with relationship edges like "teammate_of" and "prefers." Memory retrieval involves graph traversal and relationship reasoning.
Key Research & Implementations:
MemGPT - The pioneering work by Packer et al. in "MemGPT: Towards LLMs as Operating Systems" introduced the concept of treating LLMs like operating systems with hierarchical memory management, moving beyond simple context windows to persistent memory stores.
Zep - Recently published research by the Zep team in "Zep: A Temporal Knowledge Graph Architecture for Agent Memory" (2025) demonstrates their temporal knowledge graph approach.
mem0 - The team published "Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory" (2025), introducing a novel memory architecture that dynamically captures, organises, and retrieves salient information from ongoing conversations
Think of it as turning conversations into a knowledge graph where the AI can reason about relationships, temporal sequences, and complex entity interactions.
Pros:
Excellent for reasoning about people, entities, and rules
Better at modelling human-like relationships and contexts
Handles temporal aspects well (when did something happen?)
More structured and predictable than vector search
Can capture complex multi-hop relationships
Cons:
Complexity grows quickly as the graph expands
Requires heavy lifting to keep graphs accurate and consistent
Harder to integrate into everyday dev stacks
Graph maintenance becomes expensive at scale
Entity extraction and relationship identification can be error-prone
As the number of hops increases, the complexity increases
4. Hybrid Approaches: Combining Multiple Memory Types

As the field matured, researchers realised that different types of information require different storage and retrieval mechanisms. This led to the development of hybrid architectures that combine multiple approaches.
How it works: These systems use different memory stores for different types of information:
Vector databases for semantic search over unstructured content
Graph databases for entity relationships and structured knowledge
Key-value stores for simple facts and preferences
Traditional databases for structured, queryable data
Several academic papers have explored multi-modal memory architectures, showing that hybrid approaches often outperform single-method systems across diverse tasks.
Pros:
Best-of-all-worlds approach - each memory type optimised for its use case
More robust and comprehensive memory coverage
Can handle both structured and unstructured information effectively
Better performance across diverse memory tasks
Cons:
Increased system complexity
Multiple components to maintain and optimise
Higher infrastructure costs
Potential consistency issues between memory stores
5. The Traditional Database Approach
And now we arrive at the oldest technology in the room: relational databases.
Relational Database Management Systems have been powering applications for over 50 years, encompassing everything from social media platforms like Facebook to banking systems. They're trusted, efficient, and battle-tested at scale. So why not use them for AI memory?
Instead of reinventing the wheel with exotic memory stores, the idea is:
Use relational databases for structured, persistent storage of memory
Layer on intelligence so AI can promote short-term to long-term memory
Give agents rules, preferences, entities, and facts in a format that just works
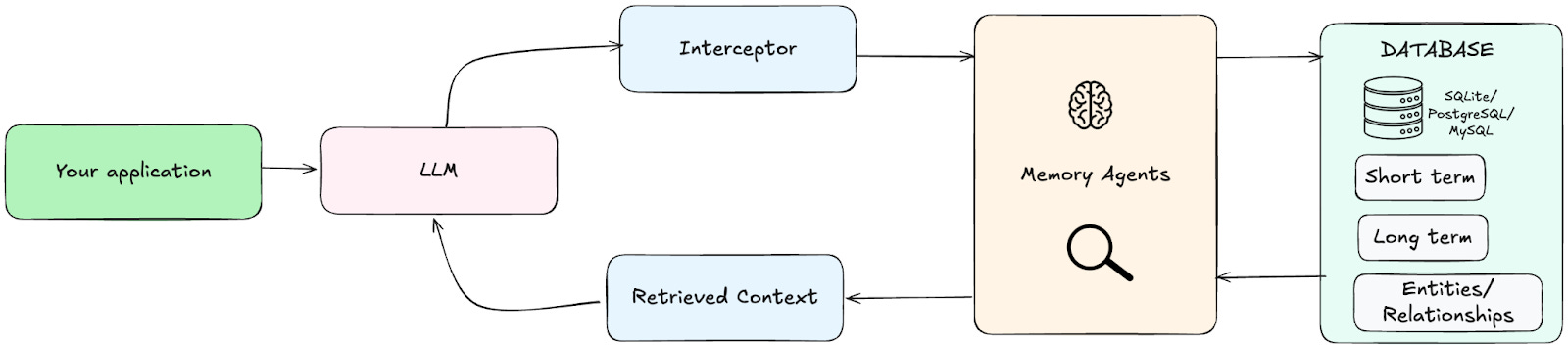
How it works: Traditional SQL databases store memory in structured tables with explicit schemas. Short-term memories (recent conversations) live in one table, while long-term memories (important facts, preferences, rules) get promoted to permanent storage. The AI uses SQL queries to retrieve relevant information, leveraging decades of database optimisation for joins, indexing, and complex queries.
That's the vision behind Memori.
Memori is an open-source memory engine built to give AI agents human-like memory on top of traditional databases. Instead of endlessly stuffing prompts or juggling vector stores, it combines short-term and long-term memory with intelligent promotion. Important facts get stored permanently, preferences are remembered, and conversations feel continuous.
Handling Relationships & Entities in SQL: Unlike graph databases that store relationships as edges, Memori defines relationships within SQL using specialised memory types and structured data models. It uses four distinct memory categories:
Entity Memory - stores people, technologies, projects as structured records with attributes
Rules Memory - captures user-defined guidelines and constraints
Short-term Memory - recent conversations with context links
Long-term Memory - permanent insights with relational references
Relationships are modelled through foreign keys, JSON fields for complex attributes, and intelligent tagging systems. For example, "John is my teammate who prefers Python" gets stored as an entity record for John with relationship attributes (teammate_of: user_id) and preference tags (languages: ["Python"]), rather than requiring a separate graph structure.
Some of the features include:
Dual Memory System (short-term and long-term)
Essential Memory Promotion — AI decides what's worth keeping
Rules & Entities — like "I prefer Python" or "John is my teammate"
Universal Integration — works with any LLM stack (OpenAI, Anthropic, LiteLLM)
Database Agnostic — supports PostgreSQL, MySQL, SQLite
Advantages of this approach:
Built on proven, scalable database tech that enterprises already trust
Structured memory (rules, entities, preferences), not just fuzzy search
Reliable, production-ready architecture with ACID compliance
Easy for developers to adopt, no need to learn a whole new system
Excellent performance characteristics and a mature tooling ecosystem
Natural fit for applications that already use SQL databases
Cons:
Limited semantic search capabilities compared to vector databases require exact matches or manual similarity logic.
It may struggle with unstructured, conversational data that doesn't fit neatly into predefined schemas.
Wrap-Up
AI memory has come a long way, from brute-forcing everything into prompts, to vector search with RAG, to sophisticated graph-based systems, hybrid architectures, and now back to something we've trusted for decades.
The truth is, building memory for AI isn't about reinventing storage. It's about combining the reliability of old systems with the intelligence of new ones. Each approach has its strengths:
✅ Prompt engineering works for simple, short-term needs
✅ Vector databases is good at semantic search over large, unstructured datasets
✅ Graph databases are great for complex relationship modelling and entity reasoning
✅ Hybrid systems provide comprehensive coverage, but with added complexity
✅ Traditional databases offer reliability, structure, and easy integration
👉 Follow our Newsletter on X: Daily AI Insights
This Week in AI
VaultGemma - Google launched the largest open model trained from scratch with differential privacy
Qwen3-Next-80B-A3B - Qwen launched yet another effiecient model.
LLM has limitations - Fei-Fei Li says language models are extremely limited. The models are just very advanced pattern matchers.
Connectionism - Thinking Machines Lab launched their research blog to share some cool works they are doing in AI.
LLM Distillation - Nebius announced their new online webinar for fine-tuning and LLM distillation.
Sukriya🙏🏼 See You Again Next Week! Till Then Keep Learning and Sharing Knowledge with Your Network
Nice blog amitesh